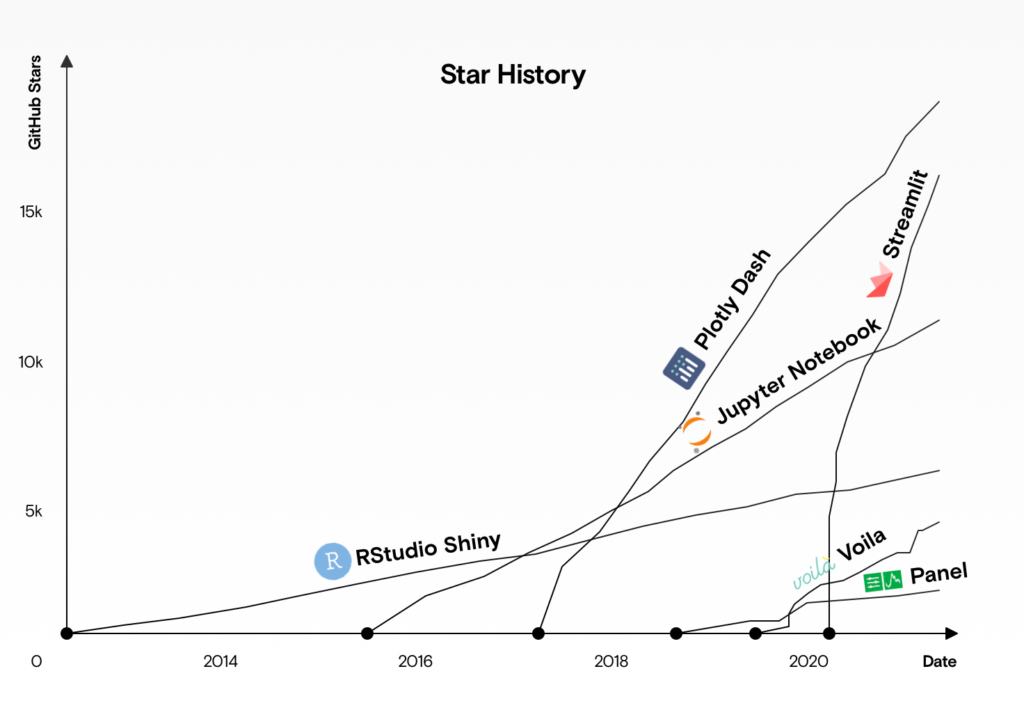
Pythonベースでインタラクティブなダッシュボードを作成するためのフレームワークの1つにStreamlitがあります。現在最も人気があるフレームワークはDashのようですが、下のグラフのようにGithub上では2020年以降Streamlitの人気が急激に伸びていることが分かります。
StreamlitはDashのように見た目の細かいカスタマイズができないという欠点がありますが、ある程度デフォルトの設定を受け入れることができれば非常に簡単にダッシュボードを作成することができます。今回はStreamlitとPlotlyでKaggleデータの特徴量とラベルを可視化するダッシュボードを作ります。
データとダッシュボード
今回はkaggleのtabular playground series Mar 2021のデータを使います。このデータは下表の通りサンプルidと19個のカテゴリカル変数(cat0 ~ cat18)と11個の連続変数(cont0 ~ cont10)、そして2値(0,1)のターゲット変数が含まれます。

このkaggleデータを使って以下のようなダッシュボードを作成します。
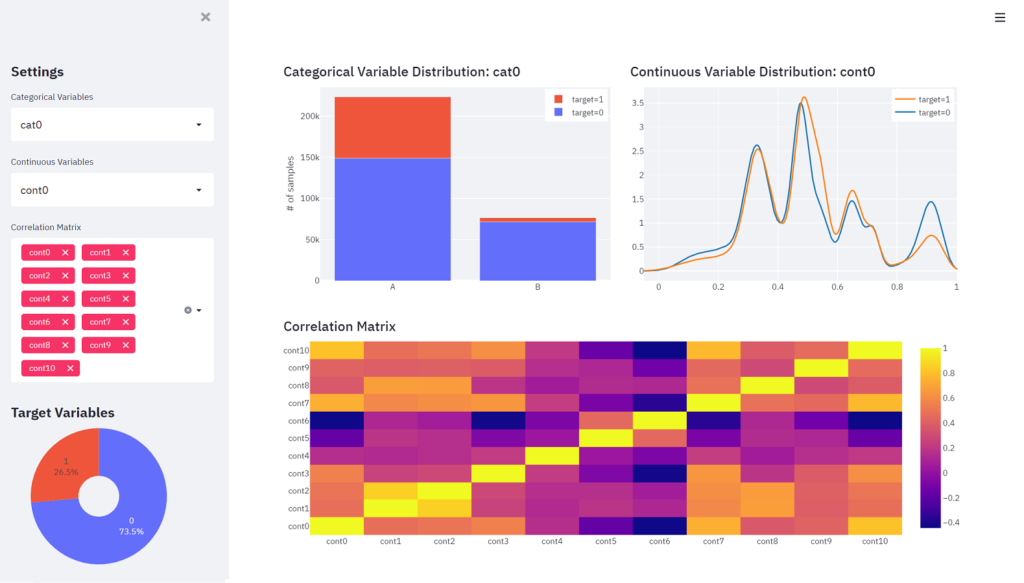
左側のサイドバーで分布を確認したいカテゴリカル変数と連続変数を1つずつ選択し、また相関関係を確認したい連続変数を複数選択すると、右側のコンテンツにそれぞれのグラフが表示されるようなダッシュボードを作成します。サイドバーの下側にはターゲット変数のサンプル数の割合を確認するための円グラフを表示させます。
Streamlitのインストール
StreamlitとPlotlyをインストールします。
conda install -c conda-forge streamlitconda install -c plotly plotly必要なモジュールをインポートします。
import pandas as pd
import plotly.figure_factory as ff
import plotly.graph_objects as go
import streamlit as st次に前節で紹介したデータを読み込み、カテゴリカル変数と連続変数のカラム名のリストを作成します。
df = pd.read_csv('data/data_sample.csv')
vars_cat = [var for var in df.columns if var.startswith('cat')]
vars_cont = [var for var in df.columns if var.startswith('cont')]Streamlitの基本的な使い方
ダッシュボードのコンポーネントを作成していく前に、スクリーン全体を使ってグラフが表示されるように設定します。
st.set_page_config(layout="wide")layout=”wide”としないとグラフが中心よって両サイドに不必要な空白が生まれます。
次にStreamlitの基本的な使い方ですが、Streamlitではst.メソッド名と記載するだけで、ダッシュボードのコンポーネントを簡単に追加することができます。サイドバーに必要なコンポーネントは以下の通りです。
- Settingsと見出しの大きさで表示
- カテゴリカル変数を選択するためのドロップダウンリスト
- 連続変数を選択するためのドロップダウンリスト
- 連続変数を複数選択するためのドロップダウンリスト
- Target Variablesと見出しの大きさで表示
- ターゲット変数の割合を表示する円グラフ
これらをStreamlitで表現すると次のコードの# Layout (Sidebar)以下のようになります。コードの上半分は円グラフを作成するためのコードです。
# Graph (Pie Chart in Sidebar)
df_target = df[['id', 'target']].groupby('target').count() / len(df)
fig_target = go.Figure(data=[go.Pie(labels=df_target.index,
values=df_target['id'],
hole=.3)])
fig_target.update_layout(showlegend=False,
height=200,
margin={'l': 20, 'r': 60, 't': 0, 'b': 0})
fig_target.update_traces(textposition='inside', textinfo='label+percent')
# Layout (Sidebar)
st.markdown("## Settings")
cat_selected = st.selectbox('Categorical Variables', vars_cat)
cont_selected = st.selectbox('Continuous Variables', vars_cont)
cont_multi_selected = st.multiselect('Correlation Matrix', vars_cont,
default=vars_cont)
st.markdown("## Target Variables")
st.plotly_chart(fig_target, use_container_width=True)ドロップダウンリストで選択した変数名を後段のグラフの作成で使用するので、cat_selected, cont_selected, cont_multi_selectedに格納します。selectboxとmultiselectの第1引数はリストの上に表示させる文字列で、第2引数は選択する項目リストです。またmultiselectのdefault引数には最初から選択済みにする項目を設定することができ、今回は全ての連続変数を選択済みに設定しています。
今までのコードをapp.pyに保存して、terminal上でstreamlit run app.pyと実行すると次の画面がブラウザ上に表示されます。
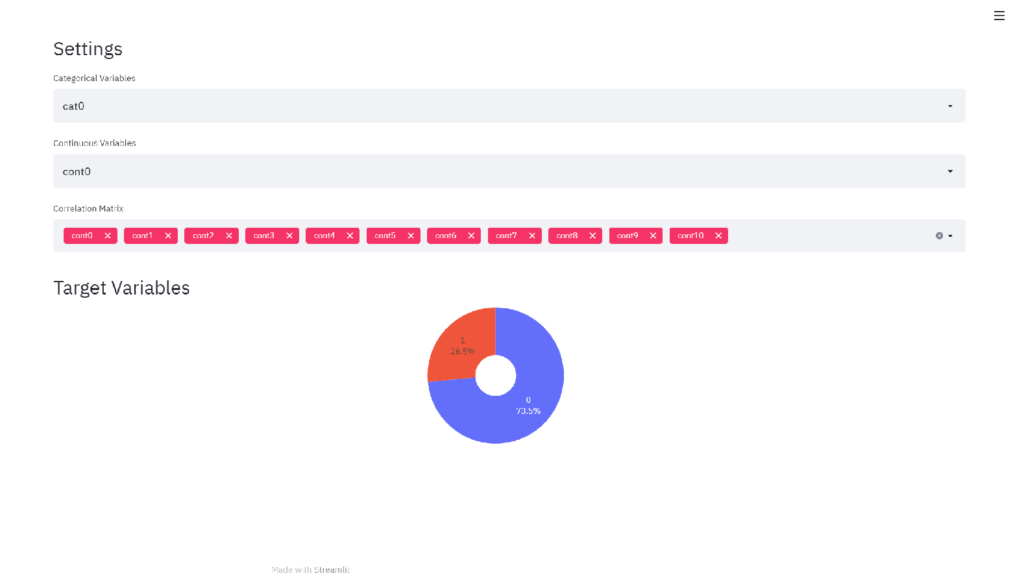
サイドバーの作成
前節のコンポーネントをサイドバーに表示するためには、stとメソッド名の間にsidebarを追加します。
# Layout (Sidebar)
st.sidebar.markdown("## Settings")
cat_selected = st.sidebar.selectbox('Categorical Variables', vars_cat)
cont_selected = st.sidebar.selectbox('Continuous Variables', vars_cont)
cont_multi_selected = st.sidebar.multiselect('Correlation Matrix', vars_cont,
default=vars_cont)
st.sidebar.markdown("## Target Variables")
st.sidebar.plotly_chart(fig_target, use_container_width=True)コードを変更すると先ほど立ち上げた画面の右上にRerunボタンが表示されるので、そのボタンを押すと画面が更新されます。

簡単にサイドバーに表示させることができました。
コンテンツのグラフの作成
ダッシュボードの右側のコンテンツ部分に表示するグラフをplotlyで作成します。
# Categorical Variable Bar Chart in Content
df_cat = df.groupby([cat_selected, 'target']).count()[['id']].reset_index()
cat0 = df_cat[df_cat['target'] == 0]
cat1 = df_cat[df_cat['target'] == 1]
fig_cat = go.Figure(data=[
go.Bar(name='target=0', x=cat0[cat_selected], y=cat0['id']),
go.Bar(name='target=1', x=cat1[cat_selected], y=cat1['id'])
])
fig_cat.update_layout(height=300,
width=500,
margin={'l': 20, 'r': 20, 't': 0, 'b': 0},
legend=dict(
yanchor="top",
y=0.99,
xanchor="right",
x=0.99),
barmode='stack')
fig_cat.update_xaxes(title_text=None)
fig_cat.update_yaxes(title_text='# of samples')
# Continuous Variable Distribution in Content
li_cont0 = df[df['target'] == 0][cont_selected].values.tolist()
li_cont1 = df[df['target'] == 1][cont_selected].values.tolist()
cont_data = [li_cont0, li_cont1]
group_labels = ['target=0', 'target=1']
fig_cont = ff.create_distplot(cont_data, group_labels,
show_hist=False,
show_rug=False)
fig_cont.update_layout(height=300,
width=500,
margin={'l': 20, 'r': 20, 't': 0, 'b': 0},
legend=dict(
yanchor="top",
y=0.99,
xanchor="right",
x=0.99)
)
# Correlation Matrix in Content
df_corr = df[cont_multi_selected].corr()
fig_corr = go.Figure([go.Heatmap(z=df_corr.values,
x=df_corr.index.values,
y=df_corr.columns.values)])
fig_corr.update_layout(height=300,
width=1000,
margin={'l': 20, 'r': 20, 't': 0, 'b': 0})カテゴリカル変数の分布、連続変数の分布、相関行列のヒートマップをそれぞれfig_cat, fig_cont, fig_corrに格納しています。スクリーンに収まるようにupdate_layoutで高さ、幅、余白(margin)を調整しています。
コンテンツのレイアウト
コンテンツ部分の上半分にはカテゴリカル変数の分布と連続変数の分布を並べ、下半分には相関行列のヒートマップを表示させます。カテゴリカル変数と連続変数の分布を並べるために、カラム数を設定します。
left_column, right_column = st.columns(2)今回は2つのグラフを並べるのでcolumns(2)として、left_columnに左側に表示するコンポーネントを割り当て、right_columnに右側に表示するコンポーネントを割り当てます。コンテンツ部分に表示するコンポーネントは以下の通りです。
- 左上に表示するカテゴリカル変数のグラフのタイトル
- 左上にカテゴリカル変数のグラフを表示
- 右上に表示する連続変数のグラフのタイトル
- 右上に連続変数のグラフを表示
- 下半分に表示する相関行列ヒートマップのタイトル
- 下半分に相関行列ヒートマップを表示
これらをStreamlitで表現すると以下のコードになります。
left_column.subheader('Categorical Variable Distribution: ' + cat_selected)
right_column.subheader('Continuous Variable Distribution: ' + cont_selected)
left_column.plotly_chart(fig_cat)
right_column.plotly_chart(fig_cont)
st.subheader('Correlation Matrix')
st.plotly_chart(fig_corr)コード全体を改めて表示します。
import pandas as pd
import plotly.figure_factory as ff
import plotly.graph_objects as go
import streamlit as st
st.set_page_config(layout="wide")
# Data
df = pd.read_csv('data/data_sample.csv')
vars_cat = [var for var in df.columns if var.startswith('cat')]
vars_cont = [var for var in df.columns if var.startswith('cont')]
# Graph (Pie Chart in Sidebar)
df_target = df[['id', 'target']].groupby('target').count() / len(df)
fig_target = go.Figure(data=[go.Pie(labels=df_target.index,
values=df_target['id'],
hole=.3)])
fig_target.update_layout(showlegend=False,
height=200,
margin={'l': 20, 'r': 60, 't': 0, 'b': 0})
fig_target.update_traces(textposition='inside', textinfo='label+percent')
# Layout (Sidebar)
st.sidebar.markdown("## Settings")
cat_selected = st.sidebar.selectbox('Categorical Variables', vars_cat)
cont_selected = st.sidebar.selectbox('Continuous Variables', vars_cont)
cont_multi_selected = st.sidebar.multiselect('Correlation Matrix', vars_cont,
default=vars_cont)
st.sidebar.markdown("## Target Variables")
st.sidebar.plotly_chart(fig_target, use_container_width=True)
# Categorical Variable Bar Chart in Content
df_cat = df.groupby([cat_selected, 'target']).count()[['id']].reset_index()
cat0 = df_cat[df_cat['target'] == 0]
cat1 = df_cat[df_cat['target'] == 1]
fig_cat = go.Figure(data=[
go.Bar(name='target=0', x=cat0[cat_selected], y=cat0['id']),
go.Bar(name='target=1', x=cat1[cat_selected], y=cat1['id'])
])
fig_cat.update_layout(height=300,
width=500,
margin={'l': 20, 'r': 20, 't': 0, 'b': 0},
legend=dict(
yanchor="top",
y=0.99,
xanchor="right",
x=0.99),
barmode='stack')
fig_cat.update_xaxes(title_text=None)
fig_cat.update_yaxes(title_text='# of samples')
# Continuous Variable Distribution in Content
li_cont0 = df[df['target'] == 0][cont_selected].values.tolist()
li_cont1 = df[df['target'] == 1][cont_selected].values.tolist()
cont_data = [li_cont0, li_cont1]
group_labels = ['target=0', 'target=1']
fig_cont = ff.create_distplot(cont_data, group_labels,
show_hist=False,
show_rug=False)
fig_cont.update_layout(height=300,
width=500,
margin={'l': 20, 'r': 20, 't': 0, 'b': 0},
legend=dict(
yanchor="top",
y=0.99,
xanchor="right",
x=0.99)
)
# Correlation Matrix in Content
df_corr = df[cont_multi_selected].corr()
fig_corr = go.Figure([go.Heatmap(z=df_corr.values,
x=df_corr.index.values,
y=df_corr.columns.values)])
fig_corr.update_layout(height=300,
width=1000,
margin={'l': 20, 'r': 20, 't': 0, 'b': 0})
# Layout (Content)
left_column, right_column = st.columns(2)
left_column.subheader('Categorical Variable Distribution: ' + cat_selected)
right_column.subheader('Continuous Variable Distribution: ' + cont_selected)
left_column.plotly_chart(fig_cat)
right_column.plotly_chart(fig_cont)
st.subheader('Correlation Matrix')
st.plotly_chart(fig_corr)ブラウザ上でRerunボタンを押し、ドロップダウンリストでcat3, cont6, cont0 ~ cont5を選択すると次のようにグラフが変化します。
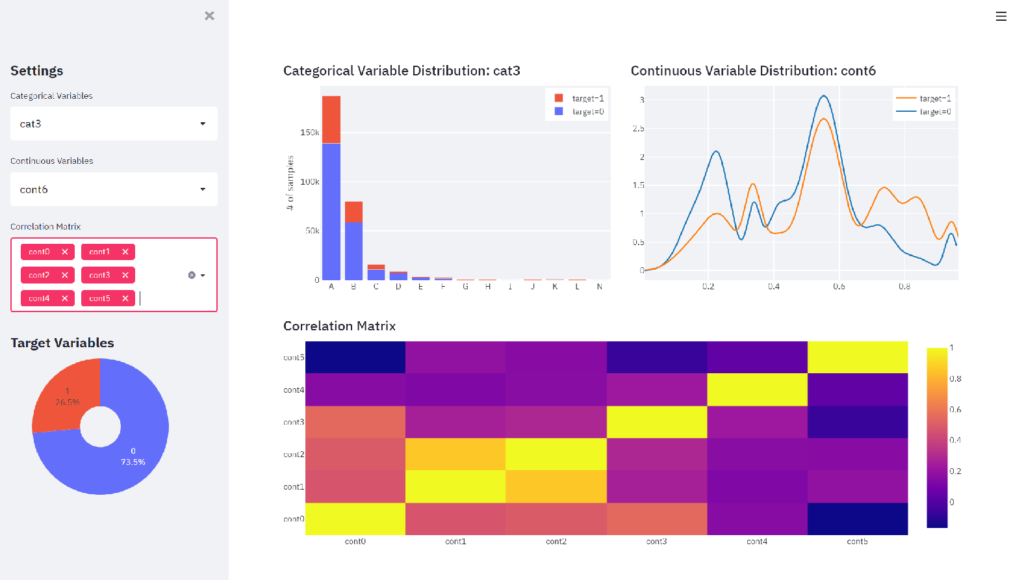
これでインタラクティブなダッシュボードが完成しました。見た目の細かなカスタマイズはできないものの、最低限のコーディングでそれなりの見た目のダッシュボードが非常に簡単に作成できることが分かりました。今後もStreamlitのコミュニティで徐々に機能が追加されていくようなので、見た目のコーディングをミニマムに抑えつつ、ロジック部分に時間を割きたい分析者にとっては有力なツールになりそうです。
今回作成したダッシュボードはStreamlit Sharingを使ってこちらに公開しています。Streamlit Sharingを使ったアプリの公開方法はこちらの記事に書いています。

StreamlitとAltairの組み合わせでもダッシュボードを簡単に作成できます。

また別の記事ではDashとPlotlyでダッシュボードを作成する手順を3回に分けて書いています。Dashは細かいカスタマイズが可能なので、手間を惜しまず理想の形に作りこみたい人にはDashもオススメです。



コメント