
Feature-engineとは特徴量エンジニアリングをするためのPythonライブラリです。Pythonを使った特徴量エンジニアリングではscikit-learnを使うことが多いと思いますが、Feature-engineはscikit-learnの良さを持ちつつ、痒いところに手が届く機能が追加されているというイメージで非常に使い勝手が良いです。今回は両者の違いに着目しつつ、Ordinal Encodingを例に使い方をまとめました。
※Ordinal Encodingはカテゴリー1、カテゴリー2,カテゴリー3,…のようなカテゴリカル変数を0, 1, 2,…に変換する手法。Label EncodingやInteger Encodingとも呼ばれる。
データ
以下のようなKaggleのタイタニックデータを使います。欠損値の処理など多少の前処理はしています。
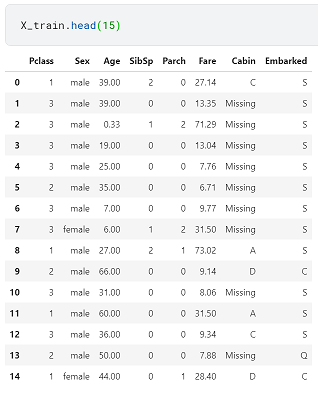
この中の特徴量SexとEmbarkedをOrdinal Encodingします。Sexはmaleとfemaleの2カテゴリー、EmbarkedはC, S, Qの3カテゴリーあり、それぞれ0,1、0,1,2に変換していきます。
scikit-learnを使った場合
Ordinal Encodingに必要なパッケージをインストールします。
from sklearn.preprocessing import LabelEncoderエンコーダーを作成します。
le1 = LabelEncoder()
le1.fit(X_train['Sex'])
le2 = LabelEncoder()
le2.fit(X_train['Embarked'])それぞれの特徴量を変換し、結果を確認します。
X_train['Sex'] = le1.transform(X_train['Sex'])
X_train['Embarked'] = le2.transform(X_train['Embarked'])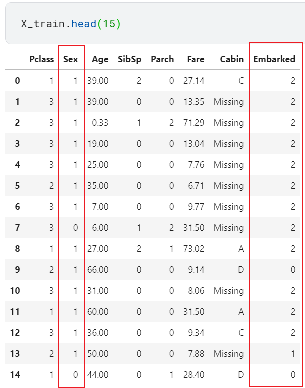
想定通りに変換されたことが確認できました。しかし、scikit-learnの場合は特徴量毎にエンコーダーを作成して各列に変換を適用しないといけないので変換したい特徴量が多い場合は多少不便です。
Feature-engineを使った場合
Feature-engineをインストールします。
pip install feature-engineOrdinal Encodingに必要なパッケージをインストールします。
from feature_engine.encoding import OrdinalEncoder他にもOneHotEncoderやCountFrequencyEncoderなど様々なエンコーダーをインストールできます。使い方もほとんど同じです。
Feature-engineはscikit-learnのAPIデザインに沿って作られているため、fit()やtransform()などの機能をscikit-learnと同じように使うことができます。
エンコーダーを作成します。この時variablesに変換したい特徴量の名前を指定することができ、複数の特徴量に対して一度にエンコーダーを作成できます。
encoding_method=’ordered’にするとOrdered Integer Encodingになります。
ordinal_enc = OrdinalEncoder(encoding_method='arbitrary',
variables=['Sex', 'Embarked'])
ordinal_enc.fit(X_train)次のように各カテゴリーに割り当てられた数値を確認することができます。

scikit-learnと同じようにtransform()で変換し、結果を確認します。
X_train = ordinal_enc.transform(X_train)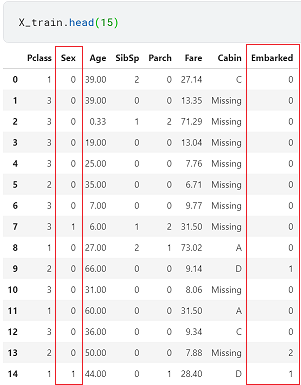
想定通りに変換されたことが確認できました。エンコードされた数値の順番が異なりますが、Ordinal Encodingは順番に意味が無いので問題ありません。
今回はFeature-engineの基本的な使い方をまとめましたが、scikit-learnのPipelineとGridSearchCVを合わせて使った少し応用的な使い方はこちらの記事をご覧ください。



コメント