機械学習モデルの出力結果を解釈するための手法は様々ありますが、Pythonパッケージのdalexを使うとそれらの手法のアウトプットを簡単にプロットすることができます。dalexのplot機能はplotlyをベースにしていることもあり、Jupyter Labで結果をプロットするまでにいくつかパッケージとExtensionをセットアップをする必要があったのでその手順をまとめました。
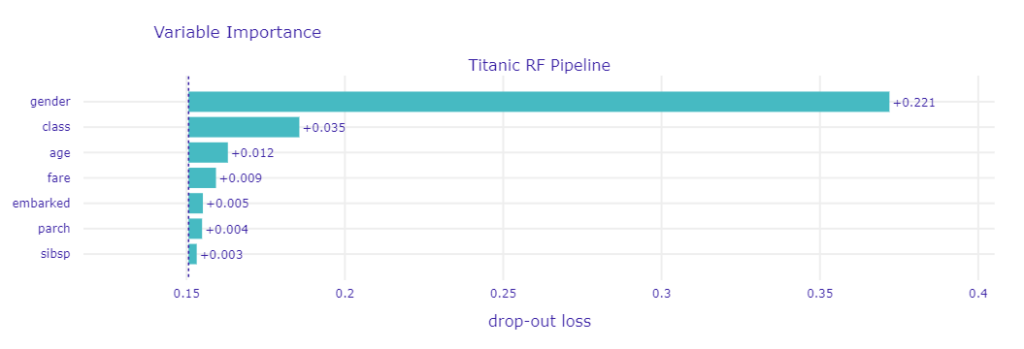
ここではあくまでdalexの出力結果(例としてRandom ForestのFeature Importanceを出力)をJupyter Labで表示させるまでの手順が分かるように書いています。dalexの使い方はExplanatory Model Analysisで詳しく紹介されています。
必要なパッケージとJupyter Lab Extensionをインストール
コマンドで必要なパッケージとExtensionをインストールしていきます。
まずはdalexをインストールします。
conda install -c conda-forge dalexdalexはscikit-learnの機能を使ってモデルを構築し、plotlyをベースにしてプロットをするのでこの2つをインストールします。
conda install -c anaconda scikit-learnconda install -c plotly plotly=4.14.3Jupyter LabそのものとJupyter Lab上でplotlyのインタラクティブなグラフを作成するためのipywidgetsをインストールします。
conda install jupyterlab "ipywidgets>=7.5"必要なJupyter Lab Extensionをインストールするにはnodejsが入っていることが前提なのでインストールします。
conda install -c conda-forge nodejsExtensionをインストールします。
jupyter labextension install jupyterlab-plotly@4.14.3
jupyter labextension install @jupyter-widgets/jupyterlab-manager plotlywidget@4.14.3以上で必要なものはインストールできました。plotlyやJupyter Lab上でplotlyを動かすためのパッケージ及びExtensionはplotly公式のgetting-startedに沿ってバージョンを指定しています。pipでインストールする方法も記載があります。
Random ForestのFeature importanceをプロット
ここではExplanatory Model Analysisを参考にRandom ForestのFeature Importanceをプロットするまでの流れを示します。基本的なプロセスは前処理、特徴量エンジニアリング及びモデル構築のPipelineをscikit-learnで構築し、そのモデル解釈するためのExplainerコンストラクタをdalexで構築して様々な結果を出力します。
まずは必要なモジュールをインポートし、dalexに入っているtitanicのデータをダウンロードします。
import dalex as dx
from sklearn.compose import make_column_transformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
titanic = dx.datasets.load_titanic()
X = titanic.drop(columns='survived')
y = titanic.survivedscikit-learnでnumerical変数とcategorical変数に必要な変換を施してRandom Forestモデルを構築するまでのPipelineを作成します。
preprocess = make_column_transformer(
(StandardScaler(), ['age', 'fare', 'parch', 'sibsp']),
(OneHotEncoder(), ['gender', 'class', 'embarked']))
titanic_rf = make_pipeline(
preprocess,
RandomForestClassifier(max_depth = 3, n_estimators = 500))
titanic_rf.fit(X, y)Pipelineを基に、dalexでExplainerコンストラクタを構築し結果を出力します。Feature importanceを算出するためにはmodel_parts()関数、プロットするためにplot()関数を使います。
titanic_rf_exp = dx.Explainer(titanic_rf, X, y,
label = "Titanic RF Pipeline")
mp_rf = titanic_rf_exp.model_parts()
mp_rf.plot()無事に以下のようなグラフをJupyter Lab上で出力できました。


コメント